I have relocated to the UK under a “family of a settled person” visa (my partner is a British Citizen). The process was… interesting. There are many forum and blog posts about it but ultimately I’d say that (outside of the UK government’s excellent website) there’s a dearth of high quality information, so I thought I’d try to summarise the process from my side.
What follows is as terse a summary of events as I could make of a process that took a significant amount of time and effort, spread out over several months. Hopefully it makes sense!
Despite everything I’m still a Firefox user and can’t see myself changing any time soon.
I have been making more and more changes to my standard Firefox configuration (outside of extensions) and keep forgetting to document them, so here they are (at least, a few of the ones I can remember – I assume I’ll find/remember for).
dom.event.clipboardevents.enabled = false
Overrides the ability of sites to handle clipboard events. This stops bad websites from preventing you from being able to paste your secure passwords into their password fields. (Docs)
network.http.speculative-parallel-limit = 0
Disable the completely rude speculative pre-connections feature which will open connections to sites based on several hints without you actually clicking on them. (Docs)
browser.pocket.enabled = false
Gets rid of that Pocket stuff which was stupidly added by Mozilla in v38.0.5. (Docs)
browser.urlbar.unifiedcomplete = false
Disables the annoying “visit” thing that pops up in the address bar as of v43:
Disables auto download and install of updates. (Docs)
browser.newtabpage.enhanced = false
Disable the ad tiles that turned up in v34.
browser.altClickSave = true
ALT-clicking a link to save it to disk worked happily until Firefox v13, when it was disabled by default.
browser.urlbar.trimURLs = false
Stops removing the ‘http’ part of URLs in the address bar. (Docs)
browser.display.background_color = #CCCCCC
I likes me a grey background.
privacy.trackingprotection.enabled = true
Enables Firefox’s tracking protection, blocking several trackers which allegedly enhances privacy. I typically have this set to false, because it can break a few things (some video players seem to rely on these trackers), but it’s good to know about. (Docs)
Google announced yesterday that they’re ending the practice of allowing advertisers to use deceptive “download” or “play” styled advertisements in AdSense ads, dubbing it a form of “social engineering”.
If you’re an Internet user that has ever tried to download or watch anything on an ad-supported site, you will have seen these stupid annoying ads. On some sites they’re styled carefully to match the look and feel of the rest of the site, so they can look like actual native content – but they’re not, of course.
They’d look something like this:
(Even worse, often they seem to link to third party versions of popular free/open source files – Adobe Acrobat Reader was always a popular one. I can only assume these third party versions are wrapped with adware or malware to justify the adverts.)
Here’s an example I just pulled off AusGamers right now:
If you’re a user, these make browsing the web irritating at best, but really they’re outright deceptive and can even be dangerous.
It’s obvious why these ads exist – there are enough users out there clicking on them to make them profitable. The cost of running the ad is less than whatever profit the advertisers are making from selling whatever the hell it is that they do.
As a result, it’s obvious why they end up on sites like AusGamers. AdSense rewards site operators on a per-click basis. Ads that perform well reward them more. On sites that offer a lot of downloads where the user’s brain is already in “GIVE ME THE DOWNLOAD BUTTON” mode, it is pretty easy to see how they work.
I have always hated these buttons for this reason. I was massively embarrassed when I started seeing these on AusGamers – putting AdSense on our download pages was something we did only relatively recently. So I decided to try to turn them off.
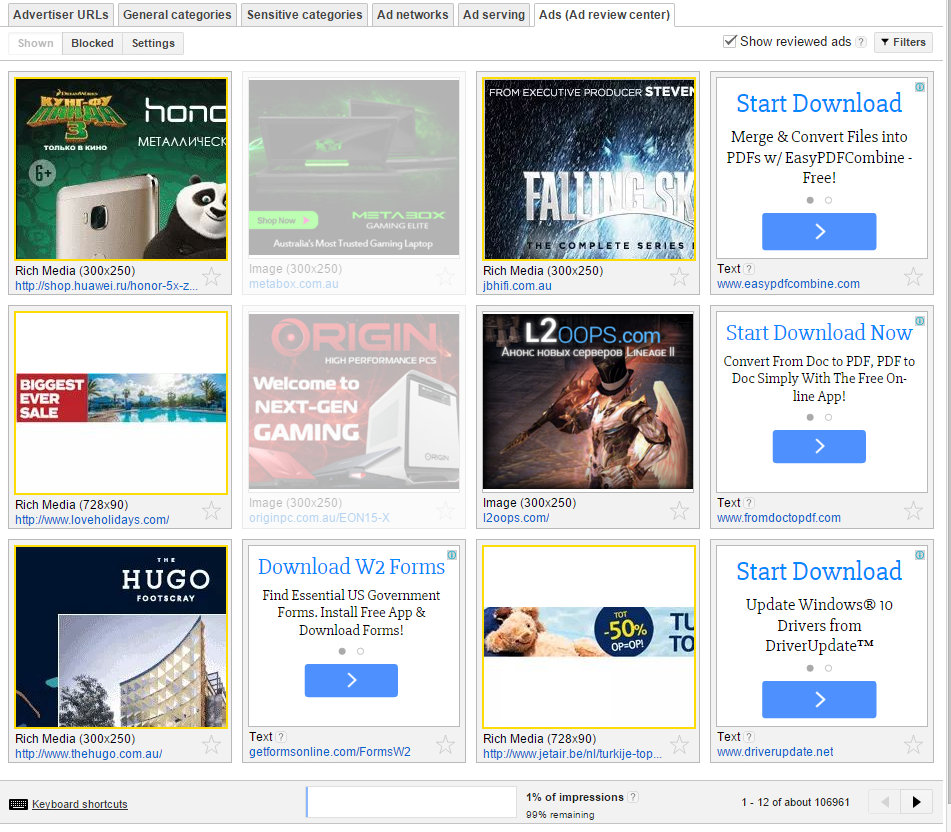
After figuring out the AdSense control panel I discovered that you could in fact block certain types of ads. However, each ad needs to be blocked individually in the Ad Review Center. This is what it looks like right now:
If you click through you’ll see there are 12 ads there – several of which are stupid download ones – but that this is only page 1 – 12 of about 106,961! Now, Google anticipated that you might not want to click through hundreds of thousands of pages of ads, so you can actually block entire ad accounts.
I went through several times when we first had these ads turn up and started blocking ads and accounts. Here’s a screen capture from a couple years ago:
This is just one page of many (… many) which contains all the ads I’d blocked. Further, I’d blocked all the accounts I could find responsible for these kind of ads. But it made basically no difference to the number of these ads that showed up on the site.
It was an unstoppable tide of bullshit ads that – despite spending many hours manually blocking ads and blocking accounts – I could do nothing about. It made me sad.
I’m relieved to see Google taking action on this. It will make the web better. It will make users safer. And it will make site operators that run AdSense feel less like jerks for having these deceptive ads on their sites.
In November 2013 I moved to the US – so as I write this, it’s been just over two years since I became a non-resident alien in the great state of Ohio.
The entire time I was here I envisioned writing a bunch to explain what it was like moving over here and trying to expand our tech company – a virtual server hosting service called Binary Lane – into the US market. But, reasons, and I never did, and I’ve felt guilty about it. Now 2016 has arrived I thought I’d try to put some words down.
The first thing I wanted to scribble were some notes about why an Australian tech company might want to consider destinations that are alternatives to Silicon Valley.
I have finally done this and posted my rather long and windy series of thoughts up on Medium. I hope it’s useful to someone and plan to write some more on the topic.
It’d been just over two years since I moved to the USA, and my time here is now almost at an end. Sadly I’m not going back home to Australia just yet – in January 2016 I’m moving to London.
There are few cities that can genuinely be considered capitals of the world – and London is at the top of the list. A nexus of culture, finance, technology, and history, it has everything I could possibly want in a place to live. (Except, perhaps, too many English people that remember the result of the last Ashes series.)
With the exception of Brisbane – which for me will always be home – there is nowhere else I’d rather be going.
I’m excited about a new adventure in a new land; from a personal point of view I’m looking forward to being able to explore the United Kingdom in more detail, and being at the doorstep to the rest of Europe. From a professional perspective, I can’t wait to check out their entrepreneurial and startup ecosystem to develop new insights that I hope to bring back to Australia.
When I first moved here, I’d planned a whole series of posts that I fully intended to write about the journey, mostly targeted to Australian startups that were looking to expand to the US – how the visa process works, what you need to do when you arrive, what it’s like living in the US, how the midwest compares to the more common destinations… As I look back, I realise I did precisely no writing on this topic.
I hope to rectify this in the coming weeks by providing some reflections of my time in the US.
This recent Dilbert comic made the rounds in startup circles recently.
It is well known within the startup community that an idea by itself is not super useful – it is the combination of the idea and execution that matters.
This belief has become almost instinctive now, to the point where people are almost dismissive of listening to ideas from those who they believe have no capacity to execute them (i.e., non-technical people). It’s always fun to hear concepts that people are working on, but hearing about Yet Another App that someone wants to make – but probably won’t – can be tiring.
While it doesn’t seem to result in outright rubbishing of ideas, there seems to be a trend to devalue the concept of “the idea”, which I think has the potential to be demoralising and de-motivational – almost the exact opposite of every other experience I’ve had in various startup communities.
I am very confident this is certainly not what is intended. It is very important to ensure that people that are interested in startup life realise that the idea is only a part – a very small part – of what makes a business.
However, it is hard enough to motivate people to consider a startup in the first place. Creating a perception that “the startup community” thinks ideas are worthless is probably not the right tone to set – everything has to start with an idea.
It’s easy to see why this comic entertains – I loved it. But the response to it (including my own!) reminded me that it’s important not to be dismissive of “idea people”, when instead we should be focusing on encouraging them to execute their idea.
Last year, Jon Stewart interviewed Nancy Pelosi on The Daily Show discussing how government procurement sort of sucks. A lot of it was the result of issues with the Affordable Care Act’s healthcare.gov site, which struggled at its launch with a series of technical problems that would make any web developer wince.
While the scale of the deployment and the bizarre state of the American healthcare system is almost completely alien to most of us in Australia, there was one part of the interview that resonated very strongly with me as a small business owner who has tried to approach government to solve their technical problems.
Stewart brought up the point that the complexity of the procurement process limits the accessibility of it to large companies – small companies are excluded simply because they don’t have the resources to devote to the tendering process.
The relevant text for those nerds (like me) who dislike video:
Stewart: “Obama’s IT guy, small company, clearly a brilliant guy – he arranged all of Obama’s Internet campaign stuff … That guy couldn’t figure out the process. He couldn’t figure out how to bid for that contract.
He said it was a 300 page document and it seems like it’s obscured like that purposefully so that the larger companies have an advantage because they have teams of lawyers and things that can do it.
…
I’m presenting it as – “Do we have a foundational problem? Is there a corruption in the system that needs to be addressed to give us the confidence that moving forward, we can execute these programmes better?”
Pelosi: “I don’t think there’s a corruption. There may be a risk aversion with going with the known and then just not being entrepreneurial enough to say, question whether that is really going to do the job.”
If you’re a small ICT company in Queensland looking to expand your customer base, you’ve almost certainly looked at the QTenders site every now and then to see what stuff is on the table.
In general I’ve found the tender documents to be very well written. They’re well organised; it’s clear what they’re trying to do and how they want to do it.
Unfortunately many of the documents are very long – just reading them can be a full day exercise.
For a small company, responding to a tender is the work time equivalent of running an entire project. They often require several people to work on. Given the often short timeframes for tender response – maybe a month – it can mean taking up a huge amount of time servicing other customers.
Arguably, this is just part of the sales process. But large companies have entire teams of sales people that do this. A mate I played soccer with actually lead a team (in mining or something, not IT), the sole purpose of which was to just reply to government tenders, having (over the years) developed a keen insight into how many they’d win versus how many they’d lose.
If you’re a large company, you can afford to do this. You can build your sales process over time and simply absorb the losses incurred by blowing a few human-months of time on responding to a tender. But if you’re a startup or an SME, you’re potentially losing 10-20% of your entire sales effort for a YEAR, working on something that you’re almost certainly not going to win – because the big companies have the tender process so streamlined. They basically have human machines for churning out responses to these things; responses that they probably know statistically how likely they are to win.
The tender process is an important part of open government procurement. But watching the giant companies that win the tenders fail again and again costing taxpayers billions of dollars is starting to wear a bit thin. We need to look at better solutions – dividing large projects up unto smaller and more manageable components and figuring out a way to let our SMEs and startups compete effectively for them, instead of them being excluded because they simply can’t afford a seat at the table.
I’m a big fan of Mozilla and have been a Firefox and Thunderbird user and advocate for many years. The last few years of development on these projects have left me somewhat disillusioned. Firefox seems to be slowly converging on Chrome, with disruptive UI changes making each update irritating, rather than exciting. Thunderbird, despite regular updates, feels like it has stagnated.
I feel like Mozilla have already won the browser wars. I’d love to see more effort going into Thunderbird and Lightning – groupware being something that open source is still really struggling with despite many valiant efforts.
It’s hard to convince myself this is a big deal; web-based groupware is pretty good these days. But I use Thunderbird every day. I’ve become almost dependent on a bunch of excellent extensions. I love having the option to be in complete control of my email.
I wrote about this in a bit more detail at Medium.
Update:
This seemed to resonate with a few people – ended up being the 18th “Most Read” article on Medium and was featured in their Technology section. Also spawned interesting discussion on reddit and Slashdot.
The full article is reproduced below.
Forgetting Firefox
It’s been more than 10 years since Mozilla released version 1.0 of Firefox. Even for someone that lived through all those early web years it’s hard to imagine what it was like back then — almost everyone who used the web was using Internet Explorer on Windows, something which seems almost comical now in this age of Chrome and Safari and mobile browsing.
Back then though, there wasn’t much of a choice. There were a few alternatives, but many sites were built only with IE in mind, simply due to its huge market share (almost 80%). So chances were good that even if you were running something else, you’d have IE ready to fire up in the background.
I’ll confess that during this time, our web development company was building for IE. Testing in other browsers — if it happened at all — was cursory. We’d fix specific issues in other browsers if they were reported by users, but these were pretty rare.
Today, of course, it is almost the exact opposite. Chrome has the lion’s share in the desktop world. IE is still a respectable second place, though only a fraction ahead of Firefox. Mozilla’s mission of 2004 — to break up the web’s monoculture and near-complete dependence on Internet Explorer — would seem to be over.
Microsoft can no longer afford to let IE not comply with certain standards. Indeed, the argument can be made that it is a second class web citizen and is, more often than not, forced to play catch up to everyone else.
The Mozilla Foundation was established in 2003 to “preserve choice and innovation on the Internet”. I believe they’ve succeeded — perhaps beyond their wildest dreams — in the web space. Who would have thought a small foundation creating open source software could upset one of the biggest software companies in the world and help completely disrupt their near-total market dominance?
Mozilla and Firefox Today
Since Google introduced their Chrome browser, Firefox use around the world has been shrinking. While it is far from an afterthought, it’s clear that many users have jumped ship to Chrome — usually citing performance as the main reason. I listen to the expressions of surprise from my colleagues and peers when they hear about someone using Firefox — “why haven’t you switched to Chrome?”, typically resulting in another convert by the end of the conversation.
Further, as more and more browsing is done on mobile devices — where the trend again seems to be to use the standard browser that ships with the operating system — the growth of Firefox seems an unlikely prospect.
However, Mozilla has not stopped working on Firefox. Indeed, change has continued at a furious pace — back in 2011 they switched to a rapid release schedule, aiming to ship a new release build of Firefox every six weeks, calling this change “a major improvement in our ability to respond to the needs of our users and the web”.
The Firefox version number has rocketed skyward. From 2004 to 2010, Firefox went from version 1.0 to 3.6.13. Once their rapid release schedule kicked in though, they burned all the way through to version 33.0, released in October 2014.
Of course, the version numbers aren’t really indicative of much — though some critics deride the versioning strategy as nothing more than a way to try to seem as “fresh” as Google Chrome’s much higher version numbers. What really matters is what has changed under the hood, and there have certainly been a huge number of changes.
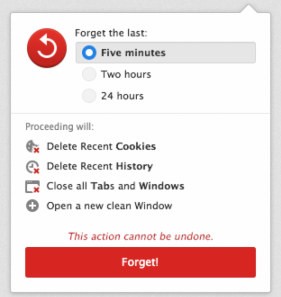
Although, as I write this, it’s hard to think of what those changes have been. I certainly can’t think of any new feature that made me go “oh, that’s cool” or “great, I’m glad they finally fixed that” or “sweet, this rocks!” Maybe the background updater? WebRTC support, although I haven’t used it yet. The main feature of their 10 year anniversary special release was just a widget that lets you forget certain parts of your history and some new built-in search options.
Sadly, I have almost come to dread new releases. “What is going to break this time?”, I think. “What random interface changes are they going to introduce?”
However, this essay isn’t about railing on Mozilla for problems with Firefox releases. This is an issue, but there are already many words devoted to covering this in great detail — simply look at basically any Slashdot discussion about any new release and you’ll see a laundry list of complaints (my favourite is the one when they introduced the new Australis redesign).
No, my problems with Firefox are something I see as merely a symptom of the real problem:
Mozilla has already won the browser wars.
Their core mission has been accomplished. Their goal was never to create the most popular browser in the world, or the one with the best UX, or the one with the most features, or the one with the best developer mode. Their goal was to “preserve choice and innovation on the Internet”.
It would be foolish to say a monoculture will never arise again (Google are making some scary moves with Chrome-only web applications). But at this point in time while Chrome is the ascendant browser (largely at the expense of Firefox), Mozilla’s ability to impact the web in general is greatly reduced. (Arguably, the rate of change and the dramatic impact to the long-standing UI and UX could be driving more people away from it.)
Mozilla are not focusing all their efforts on the web alone. While Firefox seems to get the lion’s share of funding and attention, they’ve been extremely hard at work building Firefox OS, an operating system for mobile devices. Mozilla Labs continues to spit out a range of interesting R&D projects.
One other well-known and widely used Mozilla project is, of course, the Thunderbird email client. In 2012, after several years of active development and significant improvements, Mozilla decided that Thunderbird would basically be put into caretaker mode, letting the community drive development.
The groupware mess.
Before going forward, I want to touch on the state of groupware — that being the collection of applications, tools and services that organisations use to collaborate digitally, typically including email and calendar systems.
For many years, Exchange was the uncontested leader in this market. Microsoft’s dominance in this area was almost complete — nothing packed the same level of functionality for communication and collaboration with the same ease of deployment, not to mention the integration with the rest of the Microsoft software ecosystem. Sure, it wasn’t without problems, but it was as close to a groupware standard as existed.
Then Google came along, sniffing a great opportunity. Google Apps offered simple pricing and an experience that almost everyone was pretty familiar with due to the penetration of Gmail and Google Calendar — companies could switch over and not have to worry too much about retraining. Companies heavily entrenched with Outlook couldn’t switch, but for the vast majority of small businesses it was a pretty attractive deal.
Fast forward a bit to 2015 — Amazon have just announced WorkMail, an e-mail and electronic calendar service, targeted directly at customers of Microsoft and Google. It’s clear they’ve been thinking about this for a while; as one of the biggest cloud providers and software developers they’re uniquely positioned to offer services around the planet.
Having these three options will be a great improvement for consumers. The growth of cloud shows little sign of curbing and the increasing simplicity it offers to businesses — “we no longer have to deal with keeping Exchange running?!” — is pretty appealing. So as long as you’re happy with paying another organisation to hold onto some of the critical data of your business, you’re fine.
If you’re turning to open source, there are a few options. I can only claim personal experience with Zimbra — it’s a great piece of software, if a bit fiddly to get and keep running. Finding the one that matches your requirements can be tough and time consuming.
Ultimately we found that we couldn’t stop people wanting to use Outlook. It has a lot of momentum. It has polish and features that make the open source equivalents feel somewhat clunky, awkward and limited by comparison. Zimbra works with Outlook (if you pay for the commercial version with the magic connector), or you can just use the web interface.
But people who are serious about email typically want to use a serious email client. They want plugins and heaps of interface options. They want instant response times. They want a local copy so it can be accessed offline (or if you’re truly hardcore, you don’t want your email on someone else’s server in the first place). You want to have the files that make up your email collection stored on your own disk, so you can back them up and manipulate them at your convenience.
And so we come back to Thunderbird.
Mozilla’s chance to really impact groupware.
Mozilla has already done more for groupware than just about anyone, simply by the existence of Thunderbird in the state it is in today. (Lightning, their calendar application/extension is also a Big Deal.)
But it seems an opportunity exists for Mozilla to once again take the lead in a critical aspect of Internet infrastructure. Microsoft’s blood is in the water as their iron grip on key parts of both the home and business software ecosystems has started to slip.
But Mozilla is in a unique situation — they have a significant lead in the application space. Thunderbird has little mass market penetration and is far from perfect, but in terms of core functionality and stability it is very well positioned. (Lightning needs a lot more work.)
Just like Mozilla made Firefox a unifying piece in the standards-based web that we enjoy today, the opportunity exists to drive Thunderbird as a critical piece of our Internet communications infrastructure.
There are many challenges. The mass market and home users are unlikely to migrate away from web-based mail; it’s simply too convenient. But businesses and business users have a different set of priorities, and being in firmly in control of their own destiny when it comes to their assets is one of them.
Even as I write this, I can’t help but wonder if there’s any point. The cloudification of mail and calendar is just so useful and popular — how could anything turn it back?!
But then I remember what it’s like when an online service goes offline and you can’t get your provider to help out. I remember the NSA, and the risks associated with having my mail and calendar lying around on someone else’s servers. I remember promises of backups being made, only to find that after a disaster, they turned out to not work.
Thunderbird is a tool that can help ensure that users have the choice to retain control. Already a strong, feature-complete product, it’s perfectly usable right now — but it needs more. It needs focus and drive, the kind of effort that pushed Firefox into being the dominant alternative for so long. Mozilla need to re-establish credibility with users by ruthlessly fixing some of the years-old bugs and proving that they see Thunderbird as a critical piece of the Internet, like they did with Firefox.
Ultimately, Mozilla needs to make the nerds really love Thunderbird, recommending it above all else. Just as we were responsible for pushing Firefox (and now, it seems, Chrome) on civilian friends, family and businesses who defer to our geek cred when it comes to software selection… if Mozilla can convert us — we can convert them.
But we’ll only do that if it’s a legitimately better option for them. (And for us — saving us tech support calls is a big factor here!) A strong groupware client with excellent support for email and calendaring is just as important to the open Internet as a browser — for both business and personal use, we need good choices.
Mozilla: you won the browser wars. We will be eternally grateful. But we need you again to help preserve choice and innovation on the Internet. Please help us by devoting some of your incredible talent back to Thunderbird to help drive the state of groupware forward.
WordPress is a great piece of software, but it’s popularity and superficial ease-of-use combined with the fact that computers are hard means running a site on WordPress is not always as simple as it seems.
I wrote about some of the ways to reduce the risk with WordPress over on the Mammoth blog a while back.
One of the biggest risks is a WordPress site that is out of date. There are three main components to the WordPress site:
– Core: the base functionality you get on a brand new installation.
– Plugins: all the other stuff you install for functionality
– Themes: what things look like
Each component is typically its own code base, requiring maintenance and updates. Many users only know they have updates available when they log in – and many of them don’t log in that often, especially if their site is primarily static.
WPUpCheck is a simple Windows tool that polls a WordPress site periodically to check for updates in any of these three components. If it detects available updates it will bring it to your attention via a balloon in the system tray.
The goal is simple – try to ensure a larger number of WordPress sites are no longer running obsolete, out-of-date, potentially vulnerable software.
The Android permission system seemed like a great thing at first – crystal clear understanding about what each application can do on your device. However, with the latest round of updates, it has become even clear that the permission system is confusing at best and deliberately harmful for users at worst.
If you’re a privacy/security conscious, tech savvy user, you might end up poring over individual permissions for each application before deciding to install it. This can be time consuming – even experienced users might have to hit up Google to see exactly what a permission means. Sometimes you might even veto an app or an upgrade because of onerous permissions. But if you watch normal civilians use their phone, they barely even glance at the security options, during install or upgrade. I’ll even confess to giving up dealing with permissions and just installing an app because I felt I “needed” it.
Everything looked good for a while back in Android 4.3 with the discovery of the permission tweaking system which lead to “App Ops”, allowing users to selectively enable/disable permissions on a per-application basis, granting total control over what they had access to. This was perfect, but sadly was pulled in a later release, with Google saying wasn’t intended to be available. The clever hackers over at CyanogenMod restored it as part of their release, but there’s basically no way to have fine-grained control over your apps – meaning you accept everything permission that they want, or you do without.
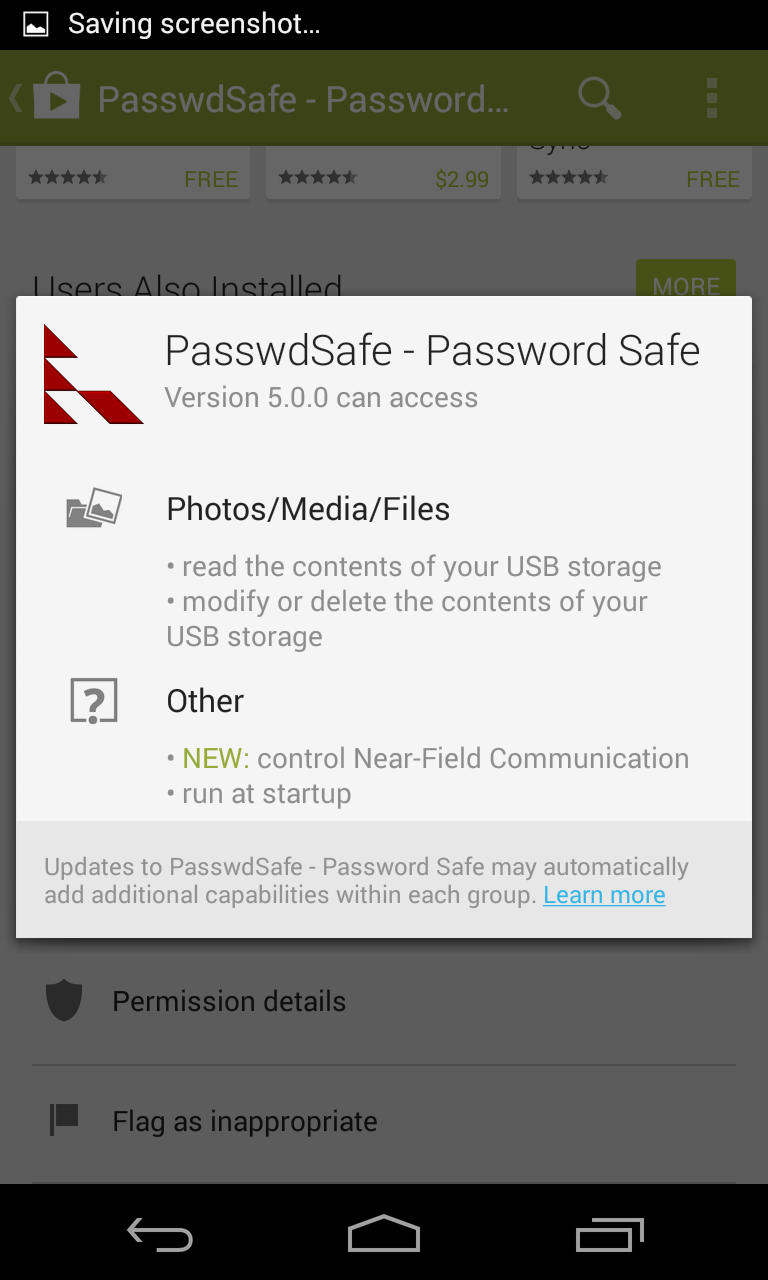
Here’s an example – I just received notice of an update for PasswdSafe:
Now, the “What’s New” notes are provided by the application developer. Sometimes they are nice enough to include details about why there was a permission change, but I would say this is generally pretty rare.
Here’s what happens when you click ‘Update’:
You only get this sort of popup when there’s a permission change. So this popup implies – to me, at least – that there’s some sort of permission change involving media, or files, or whatever.
But if you scroll to the bottom of the app page to click on the ‘Permission Details’ icon, you’ll see this:
Here you can see the new permission actually has something to do with Near-Field Communication! (So in this case, the changelog provided by the developer actually does relate directly to the permission change, though it’s not really clear until you manually inspect the permissions like this.)
While you can find the information, this current flow is totally broken. It’s infuriating that the recent change now seems to actively hide and thus mislead the user.
This UI change is a massive step back for Android; it compromises the ability of the user to make informed decisions about the software on their device.